

Felix Pinkston
July 15, 2024 18:56
Anyscale launches Replica Compaction to address resource fragmentation, improve resource utilization, and reduce the cost of Ray Serve deployments.
Enterprises adopting AI increasingly face resource utilization and cost management challenges. In particular, model serving and inference must be able to scale up and down over time in response to traffic. Ray Serve is a Ray-based scalable model serving library that helps handle these dynamics. Open source systems like Ray Serve can help manage traffic growth, but even sophisticated systems struggle to scale. Under As traffic volumes decrease, this type of resource fragmentation inevitably leads to lower resource utilization and higher costs.
Anyscale’s new Replica Compaction feature helps address resource fragmentation by optimizing resource usage for online inference and model serving. Learn how it works and how you can use it in practice.
Background: What is Ray Serve?
There are several core concepts in Ray Sub.
deployment: A deployment contains business logic or ML models to process incoming requests.
replica: A replica is an instance of a deployment that can handle requests. It is implemented as Ray Actors. The number of replicas can be increased or decreased (or auto-scaled) to match the incoming request load.
Application: An application is the upgrade unit of a Ray Serve cluster. An application consists of one or more deployments.
service: A service is a Ray Serve cluster that can consist of one or more applications.
Deployments handle incoming requests independently, allowing for parallel processing and efficient resource utilization in most cases. For example, Ray Serve allows you to create deployments for Llama-3-8B and Llama-3-70B with different resource requirements (1 GPU per replica and 4 GPUs per replica, respectively) in the same service. These two deployments scale independently in response to their traffic.
The problem of resource division
Resource fragmentation occurs when scaling activities create uneven resource utilization across nodes. As replicas increase, the autoscaler starts new nodes to handle the increased deployment load. However, as traffic decreases and models scale down, the same nodes that were needed to handle the increased load become underutilized. This is one of the most common reasons for increased costs and decreased cluster performance.
By default, when scaling a particular deployment or model (e.g. Model A), Ray Serve only considers the traffic and resource requirements for that deployment. The state, replicas, and traffic of other deployments (e.g. Model B and C) are not considered during the scaling process. Since scaling only considers one deployment at a time, resource fragmentation is inevitable as traffic changes and the cluster scales up and down.
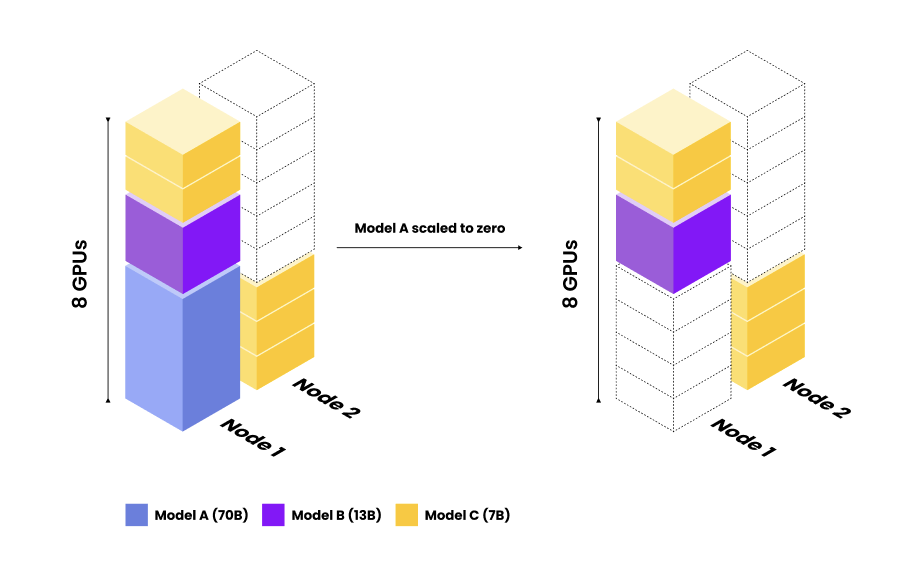
Solving Resource Fragmentation Problems with Anyscale’s Replica Compaction
Anyscale introduces Replica Compaction to address resource fragmentation. With Replica Compaction, Anyscale automatically migrates replicas to fewer nodes to optimize resource usage and reduce costs. The Replica Compaction feature has three main components.
Clone migration: Compaction monitors the cluster for opportunities to migrate replicas. When a node is underutilized, Anyscale’s Replica Compaction automatically moves replicas to other nodes with sufficient capacity. All nodes in the cluster are checked and nodes with fewer replicas available for release are prioritized.
No downtime: Migration is easy. Anyscale Services seamlessly spins up new replicas, monitors their health, reroutes traffic, and removes old replicas.
Auto-scaling integration: Anyscale Autoscaler continuously scans for idle nodes after migration and scales down nodes as needed to reduce node count and costs.
Let’s look at the same example above. Now let’s use Anyscale’s Replica Compaction. With Replica Compaction, Anyscale detects when Model A is downscaled and automatically migrates excess Model C replicas to a single node.

An example of Anyscale Replica Compaction. Anyscale Replica Compaction detects that resource fragmentation is causing unnecessary resource usage. Replicas are automatically moved to a single node (without interrupting production traffic), reducing costs and increasing utilization.
Actual Duplicate Compression: Actual Results
To test the new Replica Compaction feature, Anyscale ran live production workloads for several months. See what they did and how Replica Compaction reduced costs and increased efficiency.
Case study:
Anyscale provides a serverless API to prompt LLMs including Mistral, Mixtral, Llama3, etc. These models are deployed as replicas on the Anyscale service. The service has been running for several months and has served users at scale with over 10 models with very diverse traffic patterns.
Since launching Anyscale Replica Compaction, we have seen significant cost savings and efficiency improvements. Tokens per GPU second. In the absence of any other changes (e.g. tensor parallelism or changes in the models provided and the hardware used), overall efficiency is improved after replica compression. ~10% on average. Overall, the instance count was reduced immediately after activation. 3.7%# Despite traffic being measured by tokens, 11.2% increase During the same period, high-end GPUs such as A100 and H100 are used to serve models, leading to significant cost savings.
The impact and savings of Replica Compaction vary greatly depending on traffic distribution, number of deployments, and primary instances. In low-scalability scenarios, costs can be reduced by up to 50% (or more!).
The next step in replica compression
The team continues to improve the Replica Compaction algorithm, including working to better optimize usage and overall cost by taking into account node costs and resource types. Expect more exciting updates in the coming months.
Getting started with Anyscale
Anyscale’s new Replica Compaction feature significantly improves resource management in distributed clusters by addressing resource fragmentation. This ensures an efficient and cost-effective infrastructure for Ray Serve deployments, and promises smarter resource management through continuous improvements. Anyscale Replica Compaction is configured by default for Ray Serve applications deployed on the Anyscale platform.
Get started today!
Image source: Shutterstock