Chinese AI researchers have achieved something that many thought was light years away. In other words, it is a free, open-source AI model that can match or exceed the performance of OpenAI’s most advanced inference systems. What made this even more surprising was how the AI was able to learn on its own through trial and error, similar to the way humans learn.
“DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, shows remarkable inference capabilities.” Research papers are read.
“Reinforcement learning” is a method in which a model is rewarded for making good decisions and punished for making bad decisions, without knowing which is which. After going through a series of decisions, you learn to follow a path reinforced by the consequences.
Initially, in a supervised fine-tuning phase, a group of humans tell the model the desired output and provide context to know what is good and what is not. This leads to the next step, reinforcement learning, where the model provides a variety of results and humans rank the best results. The process is repeated over and over again until the model knows how to consistently give satisfactory results.
Image: Deepseek
DeepSeek R1 drives AI development because humans play a minimal role in training. Unlike other models that learn on massive amounts of map data, DeepSeek R1 primarily trains through mechanical reinforcement learning. Basically, experimenting with what works and getting feedback to figure things out.
“With RL, DeepSeek-R1-Zero naturally exhibits a number of powerful and interesting inference behaviors,” the researchers wrote in the paper. The model has even developed sophisticated features such as self-verification and introspection without being explicitly programmed.
As the model went through the training process, it naturally learned to allocate more “thinking time” to complex problems and developed the ability to catch its own mistakes. Researchers highlighted: “Aha moment” The model has learned to reevaluate its initial approach to the problem. This is an operation that is not explicitly programmed.
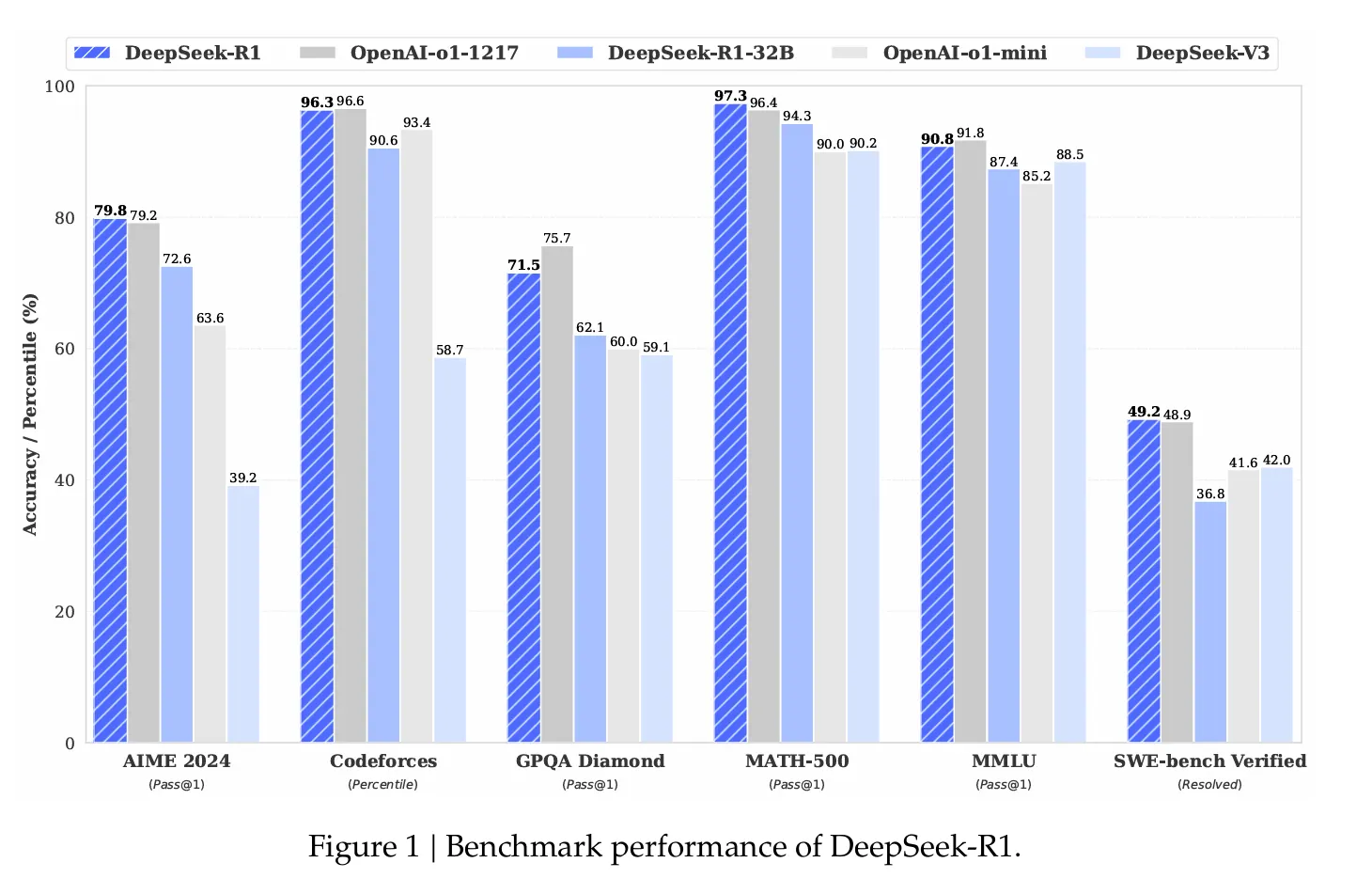
Performance numbers are impressive. In the AIME 2024 math benchmark, DeepSeek R1 achieved a 79.8% success rate, outperforming OpenAI’s o1 inference model. It performed “expert level” on standardized coding tests, achieving a 2,029 Elo rating on Codeforces and outperforming 96.3% of its human competitors.
Image: Deepseek
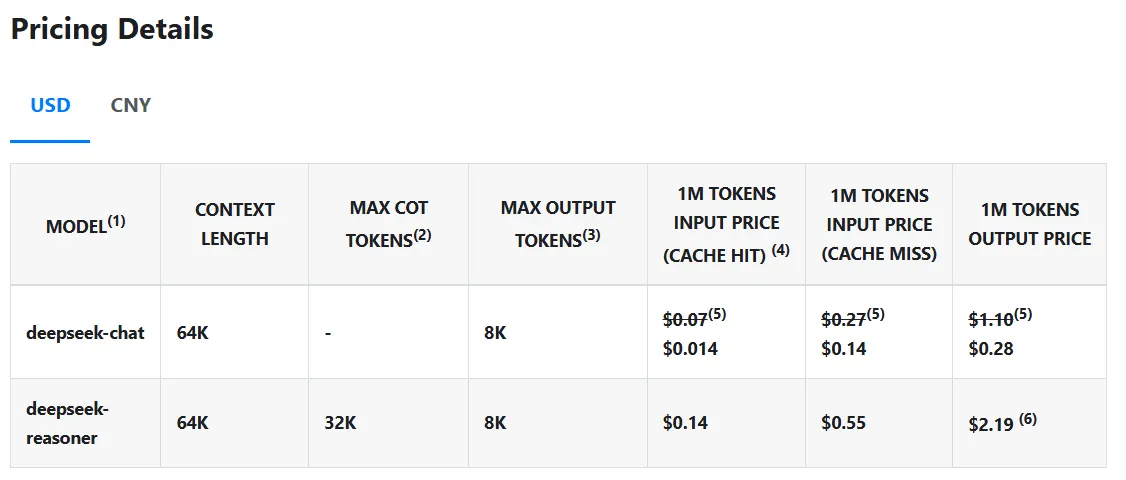
But what really sets the DeepSeek R1 apart is its cost, or lack thereof. This model is 98% cheaper, executing queries at just $0.14 per million tokens compared to OpenAI’s $7.50. And, unlike proprietary models, DeepSeek R1’s code and training methods are completely open source under the MIT license. This means that anyone can import, use, and modify models without restrictions.
Image: Deepseek
AI leaders react
The launch of DeepSeek R1 generated overwhelming response from AI industry leaders, with many emphasizing the importance of a fully open source model that matches proprietary leaders in inference capabilities.
Nvidia’s top researcher, Dr. Jim Fan delivered some of the most pointed commentary, directly paralleling OpenAI’s original mission. Fan praised DeepSeek’s unprecedented transparency, saying, “We live in an era where companies outside the U.S. are maintaining OpenAI’s original mission: truly open research that empowers everyone.”
We live in a time when companies outside the U.S. are continuing OpenAI’s original mission: truly open, pioneering research that empowers everyone. This doesn’t make sense. The most interesting results are the most likely.
Fan noted the importance of DeepSeek’s reinforcement learning approach: “This is probably the first (open source software) project to demonstrate the continued growth of the (reinforcement learning) flywheel. He also praised DeepSeek’s direct sharing of its “raw algorithms and matplotlib learning curve,” unlike any other in the industry. This is a common, hype-driven announcement.
Apple researcher Awni Hannun noted that people can run a quantized version of the model locally on their Mac.
DeepSeek R1 671B running on two M2 Ultras has faster read speeds.
Access open source O1 from home on consumer hardware.
Traditionally, Apple devices have been weak at AI due to a lack of compatibility with Nvidia’s CUDA software, but that appears to be changing. For example, AI researcher Alex Cheema was able to run his entire model after harnessing the power of eight Apple Mac Mini devices running together. This is still cheaper than the servers needed to run the most powerful AI models available today.
This means users can run a lighter version of DeepSeek R1 on their Mac with a high level of accuracy and efficiency.
But the most interesting response came after considering how close the open source industry is to proprietary models, and the potential impact these developments could have on OpenAI, a leader in AI model inference.
Emad Mostaque, founder of Stability AI, took a provocative stance, suggesting the launch would put pressure on better-funded competitors. “Can you imagine being a frontier lab that has raised $1 billion or so in funding and now can’t launch its latest model because it can’t? Can it beat DeepSeek?”
Can you imagine a “frontier” lab that has raised billions of dollars in funding but now can’t release its latest model because it can’t beat deepseek? 🐳
Following the same line of reasoning but with a more serious argument, tech entrepreneur Arnaud Bertrand explained that the emergence of a competitive open source model could be potentially detrimental to OpenAI. A lot of money per job.
“It’s essentially like someone released a phone equivalent to the iPhone but sold it for $30 instead of $1,000. “It’s really dramatic.”
Most people probably don’t realize how bad news China’s Deepseek is for OpenAI.
They have come up with a model that matches or even surpasses OpenAI’s latest model o1 on a variety of benchmarks, and at just 3% the price.
Arvind Srinivas, CEO of Perplexity AI, framed the launch in terms of market impact. “DeepSeek has largely cloned the o1 mini and made it open source.” In follow-up observations, he commented on the rapid pace of progress. “It’s kind of wild to see reasoning become commercialized so quickly.”
It’s a bit harsh to see reasoning being commercialized so quickly. We should fully expect the o3 level model to be open sourced by the end of the year, perhaps even mid-year. pic.twitter.com/oyIXkS4uDM
Srinivas said his team will work to bring DeepSeek R1’s inference capabilities to Perplexity Pro in the future.
quick lab
We did some quick tests to compare our model with OpenAI o1. We started with a well-known question for these kinds of benchmarks: “How many R’s are there in the word Strawberry?”
Typically, models have a hard time providing the right answer because they don’t work with words, but with tokens, which are digital representations of concepts.
GPT-4o failed, OpenAI o1 succeeded, and DeepSeek R1 also succeeded.
However, o1 is very concise in the inference process, while DeepSeek applies heavy inference output. Interestingly, DeepSeek’s answer had a more human feel. During the reasoning process, the model appeared to talk to itself using slang and words that are less common in machines but more widely used by humans.
For example, while pondering the number Rs, the model said to herself, “Okay, I’ll figure it out.” When discussing, we sometimes use ‘hm’ and ‘wait, no.’ “Wait a minute, let’s break it down.”
The model eventually arrived at the correct result, but it spent a lot of time reasoning and spitting out tokens. Under normal pricing terms, this is a disadvantage. However, considering the current situation, it can output much more tokens than OpenAI o1 and still be competitive.
Another test of the model’s reasoning abilities was to take on the role of a “spy” and identify the perpetrator in a short story. Select a sample from the BIG-bench dataset on Github. (The full story can be seen here and involves a school trip to a remote snowy location where students and teachers encounter a series of strange disappearances and the model must discover who the stalker is.)
Both models thought about it for more than a minute. But before we could solve the mystery, ChatGPT crashed.
However, DeepSeek came up with the correct answer after ‘thinking’ for 106 seconds. The thought process was precise, and the model was able to correct itself even after reaching an incorrect (but still sufficiently logical) conclusion.
Researchers were particularly impressed by the accessibility of the smaller version. For context, the 1.5B model is so small that it could theoretically run locally on powerful smartphones. According to Vaibhav Srivastav, data scientist at Hugging Face, even the tiny quantized version of Deepseek R1 was able to go toe-to-toe with GPT-4o and Claude 3.5 Sonnet.
“DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks, with 28.9% on AIME and 83.9% on MATH.”
Just a week ago, UC Berkeley’s SkyNove released Sky T1, an inference model that rivals the OpenAI o1 preview.
If you are interested in running the model locally, you can download it from Github or Huggingf Face. Users can download it, run it, remove censorship, or fine-tune it to apply it to different specialties.
Or, if you’d like to try out the model online, go to Hugging Chat or DeepSeek’s web portal. This is a good alternative to ChatGPT. Especially because it’s free and open source, and other than ChatGPT, it’s the only AI chatbot interface with a model built for inference.
Editor: Andrew Hayward
generally intelligent newsletter
A weekly AI journey explained by Gen, a generative AI model.